

Ingenieurhochschule Wismar, Sektion TdE/E
Fehlertolerante Mikrorechnersysteme
Mit dem Einsatz der modernen Mikrorechner in der Steuerungstechnik wachsen auch die Anforderungen an die Verfügbarkeit und Zuverlässigkeit solcher Systeme. In Fachartikeln, die sich mit den erhöhten Anforderungen an die Zuverlässigkeit solcher Mikrorechnersysteme befassen, rückt der Ausdruck Fehlertoleranz immer mehr in den Mittelpunkt des Interesses. Dieser Beitrag soll einen einführenden Überblick zum Fachgebiet der Fehlertoleranten Mikrorechnersysteme geben.
Die Entwicklung der Mikrorechentechnik war bislang vor allem durch das Bemühen um Leistungssteigerung gekennzeichnet. Erhöhung der Taktfrequenz, Verbreiterung der Datenformate, überlappte Befehlsverarbeitung und schließlich parallele Verarbeitung in Mehrprozessorsystemen sind Wege zur Leistungssteigerung. Komfortablere Betriebssysteme vereinfachen und erweitern die Anwendung. Damit wächst aber auch die Zahl der Fälle mit erhöhten Anforderungen an die Zuverlässigkeit. Der Ausdruck Fehlertoleranz rückt heute zunehemend in den Mittelpunkt des Interesses. Die vorliegende Arbeit soll helfen, auf diese Entwicklung aufmerksam zu machen und einen Überblick über Methoden, Möglichkeiten und Grenzen der Fehlertoleranz zu geben, soweit das aus heutiger Sicht möglich ist.
Zur Erreichnung einer hohen Zuverlässigkeit von digitalen Systemen gibt es zwei unterschiedliche Philosophien: Fehlervermeidung und Fehlertoleranz.
Kerngedanke der Fehlervermeidung ist es, die Fehlerursachen weitestgehend zu eliminieren, so daß ein weitestegehend perfektes System entsteht. Treten dennoch während des Betriebes Fehler auf, so führen diese zum Fehlverhalten des Systems. Kerngedanke der Fehlertoleranz ist es, das System mit einer gewissen Redundanz zu versehen, die beim Auftreten von Fehlern wirksam wird, so daß diese zu keinem Fehlverhalten des Systems insgesamt führen, d. h. toleriert werden können.
Die Prinzipien zum Aufbau fehlertoleranter Systeme sind teilweise seit längerem bekannt, wurden aber in der Vergangenheit nur für spezielle Anwendungen realisiert. Beispiele sind zentrale Rechnersteuerungen für Nachrichtenvermittlungssysteme, die eine Nichtverfügbarkeit von weniger als einer Stunde in zehn Jahren erreichen, und Steuerungssysteme der Raumfahrt mit Missionszeiten von mehreren Jahren. Der heutige Stand der Mikroelektronik erlaubt nun eine weitergehende Anwendung der Fehlertoleranz in der Rechentechnik. Das darf aber nicht nur als Anwendung bereits bekannter Prinzipien verstanden werden, sondern muß auch die Suche nach den neuen technologischen Möglichkeiten angepaßten Lösungen bedeuten.
Fehler
Die Struktur fehlertoleranter Systeme wird wesentlich von der Art der zu tolerierenden Fehler bestimmt. Ein Fehler (exakter das Wirksamwerden eines Fehlers) ist definitionsgemäß das Ereignis, das im Verlust der Funktionsfähigkeit der entsprechenden Betrachtungseinheit liegt. Bei Rechnern können Fehler in der Hardware, in der Software und als Wechselwirkungsfehler (z. B. Bedienfehler) mit der Umwelt auftreten. Die "klassischen" Fehler sind physikalischer Natur. Meist wird nach der Dauer zwischen permanenten und transienten Fehlern (Störungen) unterschieden, wobei letztere bei aus hochintegrierten Schaltkreisen aufgebauten Systemen dominieren. Die Tolerierung physikalischer Fehler
–
vor allem transienter Fehler –
stellt für fehlertolerante Systeme eine "Standardforderung" dar. Neben der Tolerierung physikalischer Fehler rückt zunehmend das sehr schwierige Problem der Tolerierung nichtphysikalischer Fehler (Entwurfsfehler der Hardware und vor allem der Software, Wechselwirkungsfehler) in den Mittelpunkt des Interesses.
Redundanz
Redundanz ist die Gesamtheit der Mittel, die ein fehlertolerantes System gegenüber einem fehlerintoleranten System enthalten muß, um seine Aufgaben erfüllen zu können. Man unterscheidet zwischen Hardware-, Software- und Zeitredundanz. Die Auswahl der zum Einsatz kommenden Redundanz ist abhängig von den zu tolerierenden Fehlern und weiteren technischen und ökonomischen Forderungen an das System. Hardwareredundanz ist nicht nur eine meist erforderliche (z. B. zum Tolerieren von permanenten Hardwarefehlern), sondern oft auch eine effektive Redundanztechnik. Hardwareredundanz erfordert aber die Bereitstellung angepaßter Schaltkreise, da sonst meist keine praktikable Lösung möglich ist. Die zwei Formen der
Hardwareredundanz sind:
Statische Redundanz
Das System enthält mehrere gleichartige und gleichzeitig aktive Komponenten, so daß durch einen Ergebnisvergleich nur in einzelnen Komponenten auftretende Fehler maskiert (d. h. unterdrückt) werden können (Maskenredundanz). Am bekanntesten ist das 2-aus-3-System, das Einzelfehler maskiert.
Dynamische Redundanz
Das System enthält mehrere gleichartige Komponenten, von denen die redundanten nur im Fehlerfall aktiv in Betrieb genommen werden.
Softwareredundanz ermöglicht das Nachrüsten von Fehlertoleranz in fehlerintolerante Systeme. Allerdings können dann nicht alle Fehler – beispielsweise keine permanenten Hardwarefehler – toleriert werden. Softwareredundanz ermöglicht die Realisierung komplexer Funktionen der Fehlererkennung, -lokalisierung und -korrektur. Allerdings sind dann die Laufzeiten der entsprechenden Programme wie auch eventuell in ihnen vorhandene Softwarefehler zu beachten.
Zeitredundanz besteht in der Wiederholung von Befehlen, Programmteilen oder ganzen Programmen und dem Vergleich der Ergebnisse. Damit können beispielsweise transiente Hardwarefehler toleriert werden. Zeitredundanz ist i. a. nur bei geringen Anforderungen einsetzbar.
Eine Sonderform der Redundanz ist die Koderedundanz. Sie ermöglicht mittels fehlererkennender und fehlerkorrigierender Kodes die Korrektur von Fehlern, die bei der Übertragung oder Speicherung von Informationen entstehen. Das wohl bekannteste Beispiel ist die Einzelbitfehlerkorrektur bei dynamischen Speichern. Koderedundanz ist aber auch bei der Informationsverarbeitung einsetzbar.
Fehlererkennung
Die in fehlertoleranten Rechnersystemen implementierten Algorithmen zur Überwachung/Fehlererkennung hängen im starken Maße von den Forderungen an die Zuverlässigkeit ab.
Bei geringen Anforderungen kann man sich mit softwarerealisierten periodischen Selbsttest begnügen. Diese Selbsttests realisieren einen von innen nach außen fortschreitenden Test des Rechners. Dieses Verfahren ist in der Literatur ausführlich beschrieben worden bis hin zu Veröffentlichungen von geeigneten Testprogrammen und Methoden zu ihrer Erstellung /1/,/2/.
Der Nachteil dieses Verfahrens ist, daß zwischen den Tests keine Überwachung erfolgt, so daß es meist nur für Anfangstestung, Offline-Testung sowie Testung nicht in Betrieb befindlicher Einheiten (Redundanztestung) geeignet ist. Für die
Online-Testung scheidet es i. a. aus.
Bei höheren Anforderungen an die Fehlererkennung ist u. U. ein erheblicher Hardwareaufwand erforderlich, den man in der Vergangenheit meist zu vermeiden suchte. Angesichts der Kostendegression für Hardware und der entgegengesetzten Tendenz für Software rücken Hardwaremaßnahmen aber zunehmend in den Mittelpunkt des Interesses.
Die Anwendung statischer Redundanz mit ihren fehlererkennenden und fehlerkorrigierenden Eigenschaften ist ein sehr leistungsfähiges Verfahren, dürfte jedoch als aufwendigste Lösung für die meisten Anwendungsfälle ausscheiden. Die Duplizierung verbunden mit Parallelbetrieb und Ergebnisvergleich sowohl von Rechnern als auch nur von Prozessoren erscheint gegenwärtig bei komplexeren Strukturen das optimale Verfahren zur lückenlosen Erkennung von Hardwarefehlern zu sein. Einige Hersteller bieten bereits angepaßte Schaltkreise an. Ein Beispiel hierfür sind die INTEL-Prozessoren iAPX 432, die ein unmittelbares Zusammenschalten zweier Schaltkreise ermöglichen und mögliche Fehler nach außen signalisieren /3/, /4/. Einen geringeren Aufwand als die Duplizierung verspricht die Anwendung fehlererkennender (meist arithmetischer) Kodes bei Prozessorschaltkreisen. Hierzu sind in letzter Zeit eine Reihe von Veröffentlichungen zu möglichen Kodes und Prozessorstrukturen erschienen /5/, /6/. Es ist aber nicht bekannt, ob derartige Schaltkreise bereits angeboten werden.
Neben den beschriebenen Verfahren werden zunehmend weitere Hardwareverfahren zur Überwachung einzelner Funktionen von Rechnern eingesetzt, wie beispielsweise Laufzeitüberwachung von Programmen, Überwachung von Speicherzugriffen und Berechtigungen usw. Diese Verfahren werden zunehmend in die Systemschaltkreise integriert. Mit ihrer Hilfe können indirekt einzelne Hardwarefehler erkannt werden, insbesondere sind sie jedoch zum Erkennen von Softwarefehlern geeignet.
So wurden z. B. in den INTEL-Prozessorschaltkreis 80386 ein Hardwareselbsttest (er erfaßt etwa 50 % der Struktur), 6
Debugregister zur Softwarefehlersuche und die Überwachung von Speicherzugriffen mittels interner MMU integriert /7/.
Diagnose
Nach dem Erkennen eines Fehlers kann durch Wiederholung des fehlerhaft verlaufenen Programmabschnitts bzw. durch Wiederholung des Tests, der zur Fehlererkennung geführt hat, entschieden werden, ob der betreffende Fehler transient oder permanent ist. Zur Lokalisierung von permanenten Fehlern muß ein Diagnoseprogramm gestartet werden. Dieses Programm ist im Prinzip gleich der Anfangstestung. Der wesentliche Unterschied besteht aber darin, daß die Zeit bei der
Offline-Testung sehr begrenzt ist. Das erfordert nicht zu lange Programmlaufzeiten des Diagnoseprogramms. In Mehrrechnersystemen sollte die Optimierung der Diagnose auf die Rechnerpausen oder die Zeit zwischen zwei Tasks erfolgen /8/. Wird mehr Zeit für die Diagnose gefordert, muß der Rechner bzw. der Rechnermodul vom eigentlichen Rechenbetrieb entbunden werden. Damit ist der Rechner für diese Zeit nicht in der Lage, die anstehenden Aufgaben zu erfüllen.
Ziel der Diagnose ist es, daß Hardwareausfälle in den Systemkomponenten einer Rechnerkonfiguration erkannt und bis auf ersetzbare Einheiten herunter lokalisiert werden. Eine Meldung nach außen erleichtert das Auffinden der defekten Systemkomponenten wesentlich. Bereits bei nicht fehlertoleranten Systemen kann damit die Reparaturzeit verkürzt und die Verfügbarkeit erhöht werden. In einem fehlertoleranten System ist die Diagnose Voraussetzung für fehlertolerantes Verhalten. Hier wird das Diagnoseergebnis zur automatischen Rekonfiguration des Systems verwendet. In Mehrrechnersystemen wird zum Beispiel von einem dreistufigen Diagnoseansatz ausgegangen:
–
Selbstdiagnose innerhalb eines Rechnermoduls
– Nachbarschaftsdiagnose zwischen unmittelbar miteinander verbundenen Modulen
– systemweite Diagnose.
Wird ein Rechnermodul ohne seine Verbindung zu anderen Modulen betrachtet, so stellt er einen typischen Mikrorechner mit CPU, Speicher und E/A-Schnittstelle dar. Die Diagnose von Hardwareausfällen kann durch fehlererkennende Kodes (spezielle Hardware ist erforderlich) oder durch Selbsttestprogramme erfolgen. Nach jedem Einschalten oder Rücksetzen eines Moduls laufen diese Selbsttestprogramme vollständig ab. Später werden sie während des Rechenbetriebes abgearbeitet. Wird Echtzeitverarbeitung gefordert, müssen die einzelnen Programmlaufzeiten beachtet werden
(online Schranke).
Bei der Nachbarschaftsdiagnose greift ein Modul direkt auf einen anderen Modul zu und informiert sich über aufgetretene Fehler bzw. über das Ergebnis des Selbsttests. Auch das Verschicken von "l'm-alive"-Nachrichten an benachbarte Module ist möglich. An dieser Stelle kann aber nicht entschieden werden, ob der Nachbarmodul defekt oder die Verbindung zu ihm unterbrochen ist. Zur Unterstützung der Rekonfiguration des Systems können die Nachbarn die Möglichkeit besitzen, einen als fehlerhaft erkannten Modul zurückzusetzen oder stillzulegen. Aufgabe der systemweiten Diagnose ist es, einen als fehlerhaft erkannten Modul allen anderen Modulen mitzuteilen. An dieser Stelle kann auch die Entscheidung getroffen werden, ob ein Modul oder nur die Verbindung zu ihm defekt ist. Es liegen nun alle Informationen für eine Rekonfiguration des Systems vor /9/, /10/, /11/.
Rekonfiguration
Der Rekonfigurationsalgorithmus beinhaltet alle Aktionen, die nach dem Auftreten und Erkennen eines Fehlers durchgeführt werden mit dem Ziel, wieder zu einem normalen Rechenbetrieb zu gelangen. Automatische
Rekonfigurationsalgorithmen lassen sich nach dem Status einteilen, den das System nach der Rekonfiguration (Systemwiederherstellung) besitzt.
Vollständige Rekonfiguration
Das System kehrt nach einer bestimmten Zeit mit seiner vollen Rechnerkapazität von der Fehlerbehandlung zurück. Es ist ein Ersatz von defekten Hardwareelementen, und eine Korrektur der Daten erfolgt. Die Korrektur der Daten kann durch fehlerredundante Kodes, durch die Rückwärtsbewegung des Systems oder die Vorwärtsbewegung erfolgen. Bei dem Prinzip der Rückwärtsbewegung
(Checkpointing) geht das System in einen fehlerfreien Zustand, der in der Vergangenheit liegt, zurück. Dazu werden im Programm Wiederaufsetzpunkte definiert und der Zustand des Systems abgespeichert. Im Fehlerfall wird ausgehend von dem zuletzt abgespeicherten Zustand ein Backup-Prozeß aktiviert. Dieser läuft in Mehrrechnersystemen auf einem anderen Rechnermodul und kann die Aufgaben des Programms lückenlos übernehmen. Bei der Vorwärtsbewegung geht das System in einen fehlerfreien Zustand, der in der Zukunft liegt, wenn Fehler im System durch Rücksetzen der betroffenen Prozesse nicht maskiert werden können. Die Vorwärtsbewegung ist aber sehr schwer zu beherrschen.
Verringerte Rekonfiguration
Das System kehrt zu einem fehlerfreien Status zurück, aber mit verringerter Rechnerkapazität. Ursache hierfür kann sein, daß keine Reservemodule mehr vorhanden sind, daß Daten oder Programmteile verloren gingen und eine Reparatur länger als die zur Verfügung stehende Zeit dauert. Es ist eine partielle Fehlertoleranz erfolgt.
Stillegung
Die Stillegung wird durchgeführt, wenn die verbleibende Rechnerkapazität unterhalb eines akzeptablen Minimums liegt. Sie hat das Ziel, eine Zerstörung von verbleibenden Daten und funktionstüchtigen Systemelementen zu verhindern und andere angeschlossene Systeme nicht zu stören. Ergebnisse, die bis zum Auftreten und Erkennen des Fehlers vorlagen, werden gerettet. Die Systemwiederherstellung kann durch die Hard- oder Software übernommen werden. Im ersten Fall ist eine spezielle Hardware erforderlich. Der prinzipielle Vorteil dieser Methode liegt in der Unabhängigkeit von Operationen, die nach dem Auftreten des Fehlers durchgeführt werden.
Im zweiten Fall muß eine spezielle Software vorhanden sein. Der wesentliche Vorteil dieser Methode ist darin zu sehen, daß bei Vorhandensein einer zweiten identischen Hardware die Systemmodule genutzt werden können, um die Fehlertoleranz zu organisieren.
Bei der Anwendung der statischen Redundanz ist Softwareunterstützung notwendig, wenn das System nach dem Auftreten eines Fehlers weiterhin ordnungsgemäß arbeiten und dazu repariert werden soll /1/, /12/, /13/.
Literatur
/1/ Ebel, B.: Mikroprozessorselbsttest. Elektronische Rechenanlagen 20 (1978) 4, S. 186
/2/ Hunger, A.: Mikroprozessor-Selbsttest auf der Basis des Befehlssatzes. Elektronische Rechenanlagen 24 (1982)1,5.8
/3/ Johnson, D.: INTEL iAX 432 – VLSI Building Blocks for a Fault-Tolerant Computer. Proc. NCC 1983, AFIPS Anaheim (1983) 5
/4/ Johnson, D.: The INTEL iAPX 432: A VLSI Architecture for Fault Tolerant Computer Systems. Computer (1984), S. 40
/5/ Geisselhardt, W.; Trautwein, M.: Fehlertolerante Mikroprozessorsysteme. Opladen 1984
/6/ Moritzen, K.: Entwurfsmethodik für Mikroprozessor-Selbstdiagnoseprogramme. Studienarbeit am IMMD III, Universität Erlangen 1981
/7/ Duzy, P.; Schallenberger, B.; Wallstab, S.; Moderne Mikroprozessoren. Elektronik München (1986) 14, S. 42
/8/ Avizienis, A.: Fault-Tolerance: The Survival Attribut of Digital Systems. Proceedings of the IEEE 66 (1978) 10, S.1109
/9/ Moritzen, K.; Wirl, K.: Verteilte Diagnose auf dem Dirmu Multiprozessor-System. Workshop
Fehlertolerante Mehrprozessor- und Mehrrechnersysteme, Erlangen 1984
/10/ Maehle, E.; Joseph, H.: Selbstdiagnose in Fehlertoleranten Dirmu-Multiprozessorkonfigurationen. Fehlertolerierende Rechnersysteme
– GI-Fachtagung, Berlin-Heidelberg 1982
/11/ Bernhardt, D.; Klein, A.: Das fehlertolerierende Mehrrechnersystem BFS. Fehlertolerierende
Rechnersysteme – GI-Fachtagung, Berlin-Heidelberg 1982
/12/ Herrman, F.: Das fehlertolerante Informationssystem 8832 / Das Fehlertoleranzkonzept. Software-Fehlertoleranz und -Zuverlässigkeit, Berlin-Heidelberg 1984
/13/ Schulz, A.: Das fehlertolerante System TANDEM T16. Sofrware-Fehlertoleranz und -Zuverlässigkeit, Bertin-Heidelberg 1984
KONTAKT
Ingenieurhochschule Wismar, Sektion TdE/E, Dr. sc. Porep, Philipp-Müller-Straße, Wismar, 2400; Tel. 53282

VEB Chemieanlagenbaukombinat Leipzig-Grimma, Stammbetrieb, OLG-Elektronik
Prof. Dr. Werner Kriesel, Dr. Klaus Steinbock
Technische Hochschule Leipzig, Sektion Automatisierungsanlagen
Partielle Fehlertoleranz für Mikrorechner-Funktionseinheiten
Problemstellung
In der Klein- und Mittelserien-Produktion werden in zunehmendem Umfang durchgängig automatisierte flexible Fertigungslinien benötigt IM, die häufig unter Integration bereits vorhandener mikrorechnergesteuerter Arbeitsstationen aufgebaut werden. Für ausreichende technologische Verfügbarkeit derartiger Systeme und bedienarme Fahrweise ist Fehlertoleranz unverzichtbar /2/. Fehlertoleranz erfordert Redundanz. Fehlertoleranz auf Systemebene bedingt eine zuverlässige Kommunikation der Systemkomponenten /3/. Speziell in die Anlagenautomatisierung eingeführte Redundanzarten /4/ können infolge ökonomischer Restriktionen nicht übernommen werden.
Vorhandene mikrorechnergesteuerte Funktionseinheiten sind i. a. nicht fehlertolerant ausgelegt. Realisierungsformen für Fehlertoleranz sind z. B. bei /5/ angegeben. Bei /6/ wird vorgeschlagen, Funktionseinheiten nachträglich mit Fehlertoleranzeigenschaften auszustatten und dabei Hard- und Softwaremöglichkeiten gleichermaßen zu nutzen. Fehlertoleranz wird dabei schrittweise, in Realisierungsphasen (Diagnose,
Rekonfiguration und Wiederanlauf) erreicht. In Weiterführung dieses Grundgedankens wird nachfolgend die Möglichkeit einer partiellen, modulbezogenen Realisierung von Fehlertoleranz vorgestellt.
Wesentliches Kriterium beider Methoden ist, daß mit vertretbarem Aufwand für das vorhandene System nachträglich Fehlertoleranz erreicht werden kann, ohne wesentliche Eingriffe in Hardware und Betriebssystem der vorhandenen Lösung vornehmen zu müssen.
Lösungsweg
Der Nutzen integrierter Fehlerdiagnose im Zusammenhang mit der für derartige Anwendungen besonders geeigneten Redundanzart definierte Leistungsminderung (Graceful Degradation) ist bei /6/ und /7/ dargestellt. Integrierte Fehlerdiagnose ist nachrüstbar; Beispiele hierzu sowie methodische Hinweise sind bei /8/ angegeben. Fehlertoleranz eines Systems besteht aus einer Summe von Maßnahmen, die auf die Tolerierung jeweils ganz bestimmter' Fehlerarten gerichtet sind, die ihrerseits nur durch ganz bestimmte Arten von Modulen verursacht werden können. Zwischen den Fehlern unterschiedlicher Modularten bestehen i. a. keine Zusammenhänge. Dies wird bei Untergliederung eines Systems nach Diagnose-Objekten deutlich. Es ist möglich, auch Rekonfiguration partiell zu realisieren.
Bei Neuentwicklungen ist die Fehlertoleranz-Strategie Bestandteil des Betriebssystems. Für die hier zu diskutierende Rekonstruktion vorhandener Systeme soll auf Eingriffe in Hardware und Betriebssystem weitgehend verzichtet werden. Hardwareänderungen werden weitgehend vermieden, indem Rekonfiguration ebenso wie Fehlerdiagnose softwareseitig realisiert wird (Anwendung software-implementierter Fehlertoleranz, vgl. /9/). Eingriffe in das vorhandene Betriebssystem lassen sich reduzieren, indem die Nachrüstung von Fehlertoleranzeigenschaften als Erweiterung mit überschaubaren, gut zu kontrollierenäen Schnittstellen erfolgt. Das Wesentliche einer dazu geeigneten Vorgehensweise wird am Beispiel der Rekonfiguration deutlich. Durch Rekonfiguration wird Redundanz nutzbar gemacht. Rekonfiguration bedeutet: Veränderung der Systemstruktur; es ändern sich Relationen zwischen vorhandenen Systemkomponenten. In ausführbaren Maschinenanweisungen ist die Systemstruktur auf Adressen abgebildet; Rekonfiguration erfordert Veränderung von Adressen (d. h., das System arbeitet anschließend unter Benutzung anderer Adressen weiter). Dazu müssen die betroffenen Adressen/Relationen identifizierbar sein. Bei vorhandenen Systemen erweist sich als Haupthindernis die i. a. völlige Regellosigkeit bei Zugriffen auf Informationen, Systemressourcen (bzw. Teilen davon,vgl. Bild 1). Die Lösung des
Rekonfigurationsproblems erfordert zunächst eine Entflechtung und Ordnung der betroffenen Relationen (vgl. Bild 2). Speziell auf derartige Problemstellungen wird in der Informatik das Prinzip der objektorientierten Vorgehensweise angewandt (vgl. /10/). Die Wirkung beruht darauf, daß ein Objekt mit allen in ihm möglichen Operationen zu einem Teilsystem zusammengefaßt wird. Seine innere Organisation ist gegenüber dem restlichen System hinter einer Schnittstelle verborgen. Wesentlich für das hier interessierende
Rekonfigurationsproblem ist dabei, daß Strukturveränderungen des Teilsystems dem übrigen System verborgen bleiben und dort keine Auswirkungen haben. Um die systemtheoretische Grundlage dieses Prinzips nutzen zu können, ist folgendes zu beachten:
Objektklassen umfassen in der Informatik ausschließlich Daten (abstrakte Datentypen, Datenkapseln). Dies ist für die Lösung von Zuverlässigkeitsproblemen nicht ausreichend, da hier auch die Hardware betrachtet werden muß. In diesem Zusammenhang erscheint es zulässig, den Objektbegriff auf stoffliche bzw. energetische Träger von Informationen auszudehnen. Die Softwarekomponenten für Diagnose des Objektes und seine Rekonfiguration sind durch den Definitionsbereich der im Objekt zulässigen Operationen berücksichtigt.
Mit diesem Ansatz eignet sich die objektorientierte Vorgehensweise zur Lösung von Rekonfigurationsproblemen für solche Systemkomponenten, die sich sowohl hinsichtlich der von ihnen repräsentierten Daten als
auch deren Träger mit Softwaremitteln (d. h. funktionell) abgrenzen lassen. Dies trifft z. B. zu auf das Hineinbringen von Redundanz in Datenspeicher oder von redundanter
(diversitärer) Software.
Eine zweckmäßige Vorgehensweise zur Realisierung partieller Fehlertoleranz wird nachfolgend an einem Beispiel erläutert /8/.
Realisierungsbeispiel
Aus Gründen der Anschaulichkeit wurde als Beispiel ein in sich fehlertoleranter Speicher gewählt. Eine vorhandene mikrorechnergesteuerte Funktionseinheit soll nachträglich fehlertolerant gegenüber Speicherfehlern werden, um veränderte technologische Anforderungen zu erfüllen, die eine sichere Verfügbarkeit von Prozeßvariablen bedingen. Der RAM des Systems wird
– unabhängig von der Schaltkreis-Anordnung – als zusammengehöriger Speicherbereich aufgefaßt, er bildet mit den gespeicherten Daten das Objekt. Vorkommende Operationen auf dem Objekt sind
–
Speichern und Lesen von Daten
– Diagnose auf Speicherfehler
– Rekonfiguration bei tolerierbaren Fehlern.
Alle dazu erforderlichen Softwarekomponenten müssen in einem Modul zusammengefaßt werden, dessen Funktionen aus dem übrigen System nur durch Parameterübergabe an einer Schnittstelle erreichbar sind.
Diagnose und Rekonfiguration benötigen keine Parameter; sie geben an das vorhandene Betriebssystem Zustandsinformationen in der für Systemnachrichten vorgesehenen Weise. Ihre Nachrüstung bereitet bei ausreichenden Systemreserven keine Schwierigkeiten.
Lese- und Schreibzugriffe sind über das gesamte vorhandene System verteilt und erfolgen bei Assemblerprogrammierung i. a. völlige beliebig (vgl. Bild 1). Ihre nachträgliche Entkopplung erfordert, daß jeder private Zugriff im vorhandenen System in einen Aufruf der Schnittstelle des fehlertoleranten Speichers mit Übergabe von Parametern umgewandelt wird (vgl. Bild 2). Dabei kann die
Registervorbelegung für den privaten Speicherzugriff i. a. als Parameter beibehalten werden, weil z. B. durch Anwendung von Testhilfen oder Speicherzugriffsroutinen häufig bereits ein Normierungseffekt gegeben ist. Bei dem nach /8/ realisierten Beispiel wurde ein zerstörungsfreier GALPAT-II-Test vorgesehen, der während des Echtzeitbetriebes zyklisch abläuft. Im Fehlerfall wird der Inhalt der fehlerhaften Speicherzelle in einen Redundanzbereich ausgelagert. Bei Zugriff auf die betroffene Variable wird automatisch der ausgelagerte Wert mit hineingebracht und der anfordernde Modul über eine mögliche Verfälschung informiert; er kann eine (problemabhängige) Plausibilitätsprüfung veranlassen.
Vom Auftreten des ersten Speicherfehlers an entsteht eine Verlängerung der Zugriffszeit in Abhängigkeit von der Anzahl der Fehler (Redundanzart: definierte Leistungsminderung). Bei den Angaben in Tafel 1 ist zu beachten, daß sie stark applikationsabhängig sind. Wenn der Prozessor der Funktionseinheit für Speichertransfer einen speziellen Operationskode aufweist, wie im Beispiel der Einchipmikrorechner U 882, so kann der Austausch der Kodefolgen in den Quelltexten in einfacher Weise mit Unterstützung durch Entwicklungssystem-Komponenten erfolgen.
Wie das Beispiel zeigt, werden alle in dem neuen Modul zusammengefaßten Funktionen gleichermaßen zur Lösung herangezogen. Nachteilig bei dem gewählten Lösungsprinzip ist eine Verlängerung der Antwortzeit durch Einführung einer zusätzlichen inneren Systemgrenze. Bei dem fehlertoleranten Systemspeicher erfolgt eine Verlängerung der Zugriffszeit, falls vorher direkter Speicherzugriff erfolgte. Demgegenüber steht der Vorteil eines nebeneffektfreien Zugriffs, der eine der häufigsten Software-Fehlerursachen bei Assemblerprogrammierung praktisch beseitigt.
Die vorgestellte Lösung wird im Chemieanlagenbaukombinat Leipzig-Grimma serienmäßig eingesetzt.
Zusammenfassung
Ergänzend zu /6/ und /7/ wird eine weitere Methode angegeben, um Fehlertoleranzeigenschaften nicht nur in Arbeitsschritten, sondern auch nach Modul-Teilfunktionen realisieren zu können. Sie ist auf alle
funktionell abgrenzbaren Diagnose-Objekte anwendbar, wenn die damit i. a. verbundene Verlängerung von Antwortzeiten vertretbar ist.
Die Methode wird am Beispiel einer Funktionseinheit mit Toleranz gegenüber Speicherfehlern erläutert. Der Vorschlag erweitert die Palette nachrüstbarer Fehlertoleranz ohne wesentliche Eingriffe in Hardware und Betriebssystem. Die Fehlertoleranz trägt dazu bei, vorhandene Mikrorechner-Lösungen künftig höheren Zuverlässigkeitsanforderungen anpassen zu können.
Literatur
/1/ Vogt, E.: Wege zur modernen Fabrik. Techn. Gemeinschaft (1987) 2, S. 15
/2/ Töpfer, H.: Bemerkungen zur Konzipierung hierarchisch strukturierter Automatisierungslösungen, messen, steuern, regeln 29 (1986) 8, S. 356
/3/ Kriesel, W.; Gibas, P.; Steinbock, K.: Neuartige Ansätze für die Technik künftiger Automatisierungsanlagen mit intelligenten Geräten. Tagungsmaterial der 5. Wiss. Konferenz "Anlagenautomatisierung", Leipzig, Wiss. Berichte (1986) 2, S. 45
/4/ Kopetz, H.: Konzepte zur Realisierung hochzuverlässiger Automatisierungssysteme. Fachberichte Messen Steuern Regeln Bd. 10, Interkama
– Kongreß 1983, Springer-Vertag, Berlin (West) – Heidelberg
– New York – Tokyo 1983
/5/ Weiss, R.: Fehlertolerante Rechnersysteme – Funktionsprinzipien u. Realisierungsformen. Regelungstechnische Praxis 25 (1983) 10, S. 408
/6/ Schäfer, M.: Fehlertolerante Mikrorechner-Strukturen/Zuverlässigkeitsaspekt. Diss. A, TH Leipzig 1987
/7/ Kriesel, W.; Schäfer, M.: Fehlertolerante Mikrorechner-Funktionseinheiten mit der Redundanzart Graceful Degradation. Mikroprozessortechnik 2 (1988) 6, S. 165
/8/ Kirste, R.: Diagnose-Software für Einchipmikrorechner in fehlertoleranten Automatisierungslösungen. Dipl.-Arbeit, TH Leipzig, SAA 1987
/9/ Dal Cin, M.: Softwareimplementierte Fehlertoleranz.
Informatik-Spektrum (1984) 7, S. 108
/10/ Pamas, D. L.: On the Criterias to be Used in Decompositing Systems into Moduls. Com. of the ACM. Vol. 15, No. 12,1972
KONTAKT
Technische Hochschule Leipzig, Sektion Automatisierungsanlagen, Prof. Dr. sc. W. Kriesel, Postfach 66, Leipzig, 7030; Tel. 394 31 36

Fehlertoleranz
Graceful Degradation

Stand-by-System
Karikaturen: Eggstein (4)
Kleines Lexikon zur Fehlertoleranz
Diversität
ist die Verwendung unterschiedlicher Komponenten gleicher Funktionalität. D. bedeutet z. B. die redundante
Implementierung von Nutzfunktionen durch mehrere verschiedenartig (zweites Team, andere Programmiersprache o. ä.) entworfene Subsysteme.
Fehlerdiagnose
Das Ziel der Fehlerdiagnose ist es, die Fehlerursachen in angebloser Zeit und mit angebbarer Wahrscheinlichkeit qualitativ und quantitativ zu erkennen (Fehlererkennung) und den Fehlerort (z. B. betroffene Module) einzugrenzen (Fehlerlokalisierung).
Fehlertoleranz
ist die Eigenschaft eines Systems, auch bei Vorhandensein interner Fehler in einzelnen Komponenten nach außen die spezifizierten Funktionen korrekt auszuführen.
Graceful Degradation
(sanfter Leistungsabfall, definierte Leistungsminderung).
Im Fehlerfall werden bestimmte Teilfunktionen eines Systems zurückgestellt, um seinen Totalausfall zu vermeiden.
Das System funktioniert damit in einem Zustand verminderter Leistungsfähigkeit, der vorübergehend tolerierbar sein muß.
Majoritätssystem (Auswahlsystem)
ist ein redundantes System, das nur dann funktioniert, wenn von n insgesamt vorhandenen Komponenten (Teilsystemen) mindestens r funktionieren. Zum Beispiel kann ein 3fach redundant ausgelegtes System noch als funktionsfähig gelten, wenn mindestens zwei Teilsysteme noch einwandfrei arbeiten, die über ein Mehrheits-Auswahlsystem herausgefunden werden (2-von-3-System).
Redundanz
ist ein funktionsbereites Vorhandensein von mehr als für die vorgesehene Funktion notwendigen technischen Mitteln, die im Bedarfsfall zur Funktionssicherung mit herangezogen werden ("Weitschweifigkeit").
Rekonfiguration
ist die Fähigkeit eines fehlertoleranten Systems, aufgrund eines Diagnose-Ergebnisses seine Struktur zu ändern.
Stand-by-System
ist eine Anordnung mit einem Reservesystem, das erst bei Ausfall des Hauptsystems eingeschaltet (aktiviert) wird, davor jedoch praktisch nicht belastet wurde. Hierbei tritt eine Unterbrechungszeit vom Erfassen des Ausfalls bis zur Beendigung des Umschaltens ein.
Verfügbarkeit
ist die Wahrscheinlichkeit dafür, daß ein System zum Zeitpunkt t intakt ist.
Wiederanlauf (Recovery)
ist die Fortsetzung der Arbeit eines Systems nach erfolgter Strukturänderung unter definierten Bedingungen und mit aktuell gültigen Informationen.
dBASE-II-Datei nicht geschlossen – was nun?
Was niemendem passieren sollte ist,
daß man eine Diskette mit einer dBASE-Datei aus dem Laufwerk entfernt, ohne die Datei vorher geschlossen zu haben.
Falls dies doch einmal passiert
Die Daten sind futsch, könnte man denken. Irrtum! Power hilft! Und das geht auch noch sehr einfach! Sie rufen das Hilfsprogramm POWER auf und lokalisieren das Laufwerk, in dem sich die defekte Datei befindet. Geben Sie nun den Befehl TYPEX ein. Es erscheinen die Directory-Eintragungen mit der Frage: select ?. Hier geben Sie die Nummer Ihres Files ein und quittieren mit der ENTER-Taste. Es wird Ihnen nun als erste Zeile die Position des ersten Blocks auf der Diskette angegeben. Sie merken sich die Werte von "T=????" und "S=???". Lassen Sie die Liste weiter laufen, so werden Sie sehen, daß Ihre Daten noch vorhanden sind. Mit ESC (Escape) können Sie diese Liste abbrechen.
Nun kehren Sie zurück ins dBASE und erstellen eine Datei anderen Namens mit der gleichen Struktur. Diese Datei kann am Ende der nun folgenden Prozedur wieder gelöscht werden.
Sie laden nun wieder das POWER, geben nochmals den Befehl TYPEX und listen jetzt die neu erstellte Datei. Wiederum merken Sie sich die Werte der Position des ersten Blocks ("T=????" und "S=???").
Anschließend lesen Sie den ersten Block der neu erstellten Datei in den RAM-Speicher Ihres Computers. Der Befehl lautet: READTSXX. Ein Beispiel mit Werten:
T=0D00 , S=012
Befehl READ D00 12XX
Nun haben Sie den ersten Block Ihrer neu erstellten Datei auf dem Monitor und können mit dem Befehl WRITE T S diesen Block auf die defekte Datei kopieren. Hier verwenden Sie nun die Position des ersten Blocks der defekten Datei. Wieder ein Beispiel:
T=0047 , S=049
Befehl WRITE 47 49
Ist dieser Blocktransfer gelungen, so laden Sie DBASE und rufen Sie mit USE Ihre Datei auf. Sie werden feststellen, daß Ihre Daten noch vollständig vorhanden sind. Viel Erfolg!
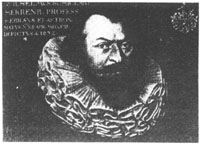
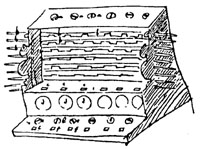
Wegbereiter der Informatik:
Wilhelm Schickard
geb.
1592 Herrenberg, gest. 1635 Tübingen.
Nach Wiederentdeckung (1957) zuverlässiger Quellen ist nunmehr mit Sicherheit erwiesen, daß bereits im Geburtsjahr Pascals, also 1623, in Tübingen eine Rechenmaschine entwickelt worden ist, und zwar von dem Tübinger Universitätsprofessor Wilhelm Schickard (auch die Schreibweisen Schickart oder Schickhardt sind gebräuchlich). Schickard war ein außerordentlich vielseitiger Gelehrter und galt nicht nur als einer der bedeutendsten
Hebraisten und Orientalisten seinerzeit, sondern er hat sich auch als Astronom, Mathematiker, Geodät, Kupferstecher und Maler hervorgetan. Jedoch ursprünglich war er Theologe, und als solcher wurde er 1611 schon Magister und Repetitor am Tübinger Stift, 1614 Diakon und ab 1619 Professor für Hebräisch, Aramäisch und weitere orientalische Sprachen. Ebenso wie sein bekannterer Onkel, der Baumeister Heinrich Schickard, war er zudem technisch und mathematisch hochbegabt. Im Jahre 1631 wurde er Professor für Mathematik und Astronomie und trat damit die Amtsnachfolge des verstorbenen Mathematikers und Astronomen M. Maestlin an, der Kepters Lehrer gewesen war. In dieser Amtszeit hat er verschiedene astronomische Geräte erfunden.
Schickard betätigte sich aber auch als Geodät. So führte er die erste Landesaufnahme von Württemberg nach eigenen kartographischen
Methoden durch; diese Methoden hat er in einem Buch dokumentiert, das nach seinem Tode noch oft aufgelegt worden ist. Des weiteren hat er mit mathematischen Mitteln das sogenannte Pothenotsche Problem gelöst, ein von W. Snellius aufgestelltes, später nach dem französischen Mathematiker Laurent Pothenot
(1660–1732) benanntes geodätisches Ortsbestimmungsproblem.
Seine Rechenmaschine baute Schickard auf Anregung des befreundeten Johannes Kepler, der ja für seine astronomischen Arbeiten viele arithmetische Operationen auszuführen hatte und an einer maschinellen Erleichterung des Rechnens interessiert gewesen sein dürfte. Zur Durchführung eines solchen Vorhabens mußte Schickard erst das Ziffernrad und die Zehnerübertragung erfinden. Seine Maschine ermöglicht neben Addition und Subtraktion auch Multiplikation und Division; es lassen sich 6stellige Operanden einstellen, das Resultatregister ist 8stellig. Es ist belegt, daß diese Maschine gut funktioniert hat. Das weiß man aus Sofort-Briefen des Erbauers an Kepler und geht auch daraus hervor, daß 1624 in Tübingen ein zweites Exemplar für Kepler hergestellt wurde, aber mit dem Hause des Mechanikers Rister verbrannt ist.
Glücklicherweise sind Schickards technische Beschreibungen (eben in Briefen an Kepler) und Anweisungen für seinen Mechaniker sowie einige Skizzen (eine davon zeigt unser Bild) erhalten geblieben und so ausreichend detailliert, daß nach diesen Angaben seine Maschine in der Neuzeit nachgebaut werden konnte. So steht nun seit 1960 ein Exemplar im Tübinger Rathaus, weitere Modelle davon befinden sich u. a. in der Geburtsstadt Herrenberg, im Deutschen Museum München sowie in der Sammlung von IBM in New York.


Fotos und Grafik: Epson
Erster 48-Nadel-Drucker
Zur CeBit '88 in Hannover stellte die japanische Firma EPSON den ersten 48-Nadel-Drucker der Welt vor. Der Matrixdrucker verbindet die Universalität der
lmpact-(Anschlag-)Technik mit einer Druckqualität, die es bisher nur bei
Non-impact-Druckern gab (anschlaglose Drucker, z. B. Laser- oder Tintenstrahldrucker). Die bewährten 9-Nadel-Drucker, die ständig verbessert wurden und werden und heute beachtliche Leistungen erzielen oder die 24-Nadel-Drucker wird der "48-Nadler" wohl nicht ersetzen, da er aufgrund des höheren Konstruktionsaufwandes wesentlich teurer ist. Für bestimmte Anwendungen wie Textverarbeitung, CAD oder Desktop Publishing (DTP) bietet er jedoch beste Voraussetzungen, da die Auflösung von 360 x 360 Punkten/Zoll (das ergibt etwa 200 Punkte je Quadratmillimeter) noch über der vieler Laserdrucker liegt.
Die Nadeln sind in vier Reihen zu je 12 angeordnet und um 1/360tel Zoll untereinander versetzt. Die Steuerelektronik feuert die Nadeln in einem Takt ab, der auch in horizontaler Richtung für einen Punkteabstand von 1/360tel Zoll sorgt. Dadurch besitzt der 48-Nadel-Drucker die volle Auflösung von 360 x 360 Punkten in einem einzigen Durchgang. Bei 24-Nadel-Druckern ist hierfür ein zweiter Druckvorgang mit versetzten Punkten, ähnlich dem NLQ-Modus bei 9-Nadel-Druckern, erforderlich (NLQ
–
near letter quality, nahe Briefqualität). Die Druckgeschwindigkeit des 48-Nadel-Druckers beträgt maximal 300 Zeichen pro Sekunde, in Schönschrift sind es 100 cps. Die Buchstabenmatrix wird bei Schönschrift in der vollen Auflösung von 360 x 360 Punkten pro Zoll wiedergegeben. Der beim Drucken anfallende Datendurchsatz ist im Vergleich zum 24-Nadel-Drucker mehrfach höher. Er entspricht bei einer Geschwindigkeit von 300 cps derjenigen eines 24-Nadel-Druckers, der mit 600 cps arbeitet. Um die Datenflut für 48 Nadeln bei hoher Druckgeschwindigkeit zu bewältigen, ist der 48-Nadel-Drucker als echtes
Multiprozessorensystem aufgebaut. Für die Codierung und den Datenfluß wird eine 16-Bit-CPU, für die Steuerung der Mechanik (Druckkopf und Papiermanagement) zusätzlich eine 8-Bit-CPU eingesetzt. Der 48-Nadler benötigt keine besondere Steuersoftware, sondern bietet bei der Wiedergabe von Text die Druckqualität auch mit der vorhandenen Software. Dafür sorgt das Betriebssystem, das alle Zeichen in der vollen Auflösung im ROM gespeichert hat. Für die Wiedergabe von Grafik arbeitet der 48-Nadler auch mit den vorhandenen 24-Nadel-Treibern. Für das volle Ausschöpfen der Druckqualität im Grafikbetrieb sind entsprechende Treiber für 48 Nadeln einzusetzen.
Der Drucker führt alle Papierfunktionen vom Einzug bis zum wechselseitigen Zustellen von Einzelblatt und Endlospapier automatisch durch. Beide Papierarten können abwechselnd bedruckt werden, ohne daß der Einzelblatteinzug entfernt werden muß. Es können ein Original und bis zu drei Durchschläge gedruckt werden. Ebenso können Briefumschläge automatisch zugestellt werden. Mit Hilfe einer Micro-Feed-Funktion läßt sich jede Papierart millimetergenau positionieren. Das Problem der richtigen Druckkopfeinstellung bei Verwendung unterschiedlicher Papiersorten im Wechsel mit Formularsätzen ist ebenfalls durch eine Automatik gelöst: Der 48-Nadel-Drucker stellt sich selbsttätig auf die Papierdicke ein. Von Haus aus ist er als Drucker im Breitformat (A3) ausgelegt. Damit wird seiner Eignung für alle Einsatzgebiete, auch Desktop-Publishing und CAD, entsprochen. Standardmäßig verfügt der 48-Nadel-Drucker über eine parallele Schnittstelle sowie über das
EPSON-Betriebssystem ESC/P, das inzwischen auf dem Druckermarkt als Industriestandard anerkannt ist. Es ermöglicht eine Zeichensatz- und Steuercodeanpassung praktisch an jedes PC-System. Als Option sind RS 232C, IEEE 488 und die 81xx-Serie lieferbar.
Das Bild zeigt schematisch einen auseinandergenommenen 48-Nadel-Druckkopf. Er besteht aus vier hintereinander liegenden Führungseinheiten mit Magneten, von denen jede über 12 Nadeln und die zugehörige Elektronik und Mechanik verfügt. Die Nadeln werden in Bohrungen durch die Führungseinheiten nach vorne durchgeführt. Im hintersten Ring ganz links sind es 12, einen Ring weiter bereits 24, dann 36 und schließlich 48 Nadeln. An der Spitze des Druckkopfes treten sie in vier nebeneinanderliegenden Reihen aus (ganz rechts). Die hinterste Führungseinheit ist auch von der Rückseite gezeigt, so daß man den Aufbau erkennen kann: Dünne Bohrungen für die Nadeln, Bohrungen für Spiralfedern und 12 Elektromagnete sind ringförmig um den Mittelpunkt angeordnet.
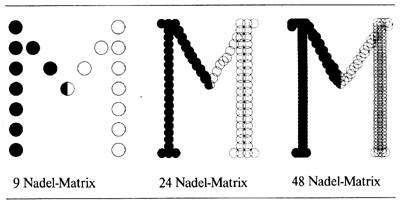
Die Grafik zeigt das Schriftbild, das 9-, 24- und 48-Nadel-Drucker nach einem Durchgang erzeugen können. Das "M" links ist in der
9-Punkte-Matrix wiedergegeben. Ein geschlossenes Schriftbild (Near Letter Quality) wird durch zweimaliges Überfahren erzeugt. 24-Nadel-Drucker (Bildmitte) benötigen nur einen Durchgang und erzeugen dennoch ein geschlossenes Schriftbild (Letter Quality). Sie besitzen zwei Reihen von je 12 Nadeln, die in etwa 0,85 mm Abstand parallel verlaufen. Der Druckkopf feuert zunächst die ersten 12 Nadeln ab, fährt dann 0,85 mm weiter und setzt die zweiten 12 Nadeln genau zwischen die Abdrücke der ersten 12. So ergibt sieh eine durchgehende Linie. Nochmals doppelt so dicht sitzen die Punkte beim 48-Nadel-Drucker (das "M" rechts). Hier werden kurz nacheinander vier mal 12 Nadeln abgefeuert. Die Punkt-zu-Punkt-Abstände betragen in jeder Richtung nur noch 1/360tel Zoll, das entspricht 0,07 mm. Dabei überschneiden sich die Punkte zu etwa 90 Prozent, so daß sich eine sehr geschlossene, gleichzeitig klare und scharte Schrift ergibt.